Introduction
This post is meant to be a brief overview of my project analyzing data from the Wisconsin X-Ray Microbeam Database for those without a background in phonology. Please email me for more information on this project, or if you have any questions/critiques!
When humans speak, each individual phoneme that makes up an utterance is produced as a messy, overlapping acoustic signal without clear boundaries between segments, yet as listeners we’re really good at interpreting these signals. Even with a lot of overlap, or coarticulation, of these segments, listeners can still perceive human speech with ease. Speech gestures, such as tongue and lip movements, also overlap in their production of speech, and can actually give another window into this process, since gestures can reveal information about segment boundaries that the acoustic signal does not! It’s not possible with many sounds to mark exactly where it begins in the acoustic signal; it could be overlapping with another sound, or there may not be good cues to mark the beginning or end of the sound. However, if there are measurements of articulatory movement (i.e. tongue and lip movement), it becomes easier to tell where each segment begins, because the data shows the point where the articulator begins to produce the segment even when there might not be any airflow through the vocal tract.
So what can this articulatory data show us? Chitoran et al. (2001)1 claim that the amount of overlap in the articulation of segments correlates with how perceivable those segments are. They showed that for stop-stop sequences in Georgian, which are more easily perceived word-medially than word-initially, have a lower degree of overlap in word-initial positions. If this correlation exists cross-linguistically, there should be evidence of overlap sensitivity wherever perceptability is low.
In order to test this, I wanted to look at sonority sequencing violations in English. Sonority sequencing says that consonants exist on a continuum of sonority, and that syllable onsets should have rising sonority and syllable codas should have falling sonority. Mattingly (1981)2 and Ohala (1990)3 argue that perceptability is a phonetic correlate of the sonority scale, so less sonorant sounds are also less perceivable. [s-stop] onsets are a violation sonority sequencing since stops are less sonorous than fricative [s], and these onsets are attested in English.
If previous work is correct, than [s-stop] onsets should have less perceptability and as a result, be more sensitive to gestural overlap. I decided to compare the gestural overlap of two complex onsets using the same gestures, but with one that violates sonority sequencing and one that does not.
The data
In order to investigate the prediction that sonority sequencing can have an effect upon gestural overlap, I will use data from the Wisconsin X-ray Microbeam Corpus. This corpus is a collection of speech production data from native English speakers reading a collection of word lists, sentences, paragraphs, and performing other speech tasks. Each speaker had sensors placed on various points on their tongue, lips, and face to track their gestures while speaking. I was able to use data from 26 speakers for this project.
The data is formatted as a Matlab table, which I use the MView package (by Mark Tiende) to view. MView’s findgest algorithm uses the tangential velocity of the displayed signal to mark various points of a selected gesture; I’ll be using its marks for gesture onset/offset. It comes out looking like this:
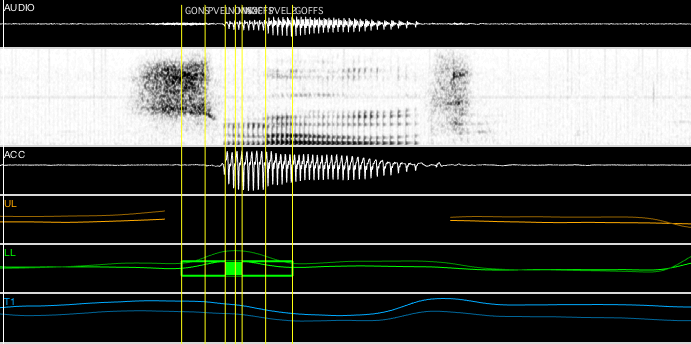
Here is a subset of the data for the word smooth being read from a wordlist. Displayed are the acoustic signal as well as the gestural signals from the pellets on the upper lip (UL), lower lip (LL), and tongue tip (T1). The vertical yellow lines are the markings found by the findgest algorithm when applied to the lower lip signal in green, which correlates to the [m] gesture. The outermost markings are the gesture onset and offset, so to find the overlap between the [s] gesture (shown by the T1 signal) and the [m] gesture in this word, I would subtract the onset of the second segment [m] from the offset of the first segment [s] (findgest measurements for T1 not shown in the image above). For this example, the overlap is 81.8 milliseconds which is a huge amount of time in speech production!
Analysis
The example above examines a sonorous sequence [sm], which we saw has a significant amount of overlap. In order to make a good comparison, I need data that meet the following criteria:
- The segments in the onset must correlate clearly with gestural signals.
- These onsets must be sufficiently represented in the dataset
- Onsets should be at the beginning of an utterance and not in the middle of a sentence.
Some segments are more difficult to analyze because it’s harder to trust the gestural signal. Take [sk] for example. There is a signal from a pellet on the dorsal surface of the tongue which could be used to measure a [k] gesture, but since I’m using the tongue tip signal to measure [s] gestures, it’s not clear that these two gestures are independent since they both involve the tongue. That’s why I chose [sm] for the previous example, since one sound correlates to a tongue gesture and one to a lip gesture. Because of that, a good contrastive example is [sp], a sequence that violates sonority sequencing but uses the sequence of gestures as [sm].
In order to compare these sequences though, I need to find good examples in the database. There’s actually not many. A typical reading task for a participant in this data is the following:

There are some examples of things that don’t work, such as the [sp] in respect (word-medial). [sw] in swiftly might be a good candidate since [w] involves a lip gesture, but the previous word as pollutes the following [s] segment. It’s best to use the word onsets in small and speaks for data like this. Additionally, there are some files where participants are just reading wordlists, but those contain very few words with the sequences I’m looking for.
Once I find all the instances of [sm] and [sp] I want in the data, I import all of the onsets into a tidyverse dataframe in R. Although Pandas dataframes in Python are my usual go-to for data analysis, I have been using R a lot lately for data wrangling and statistics, and it turned out to be perfect for this project.
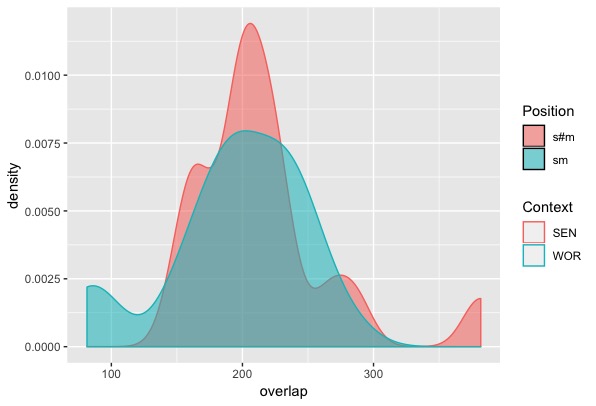
Once the data is in place, I first test a comparison of the [s] and [m] segment overlap across word boundaries (in a case like this March), versus together in an onset (as in small). Chitoran et al. showed that a stop-stop sequence should have a higher degree of overlap across word boundaries since the segments are more perceptable in that environment, rather than in a word-initial position, so in my [sm] comparison there should be no significant difference if Chitoran et al.’s story is correct.
The second comparison is that of my principal question: does sonority sequencing violation affect overlap sensitivity?
Results
In accordance with Chitoran et al.’s claims, there is no significant difference in overlap for [sm] in this March versus small [t = 1.26, p > 0.05].
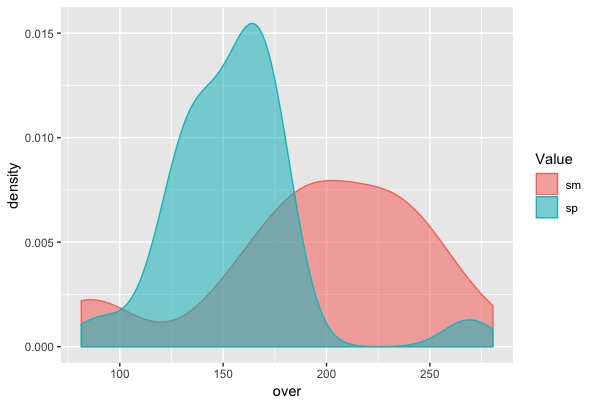
More crucially, this analysis shows that there is a significant difference in overlap for [sm] and [sp] onsets, with [sp] having less overlap overall [t = 3.227, p = 0.0025].
Discussion
This study provides evidence for the claims that perceptability affects overlap sensitivity in complex onsets in English. Additionally, I think my work provides stronger claims than the Chitoran et al. paper for two reasons:
- Their paper only used data from two speakers, whereas the data I used is from 26. This is important because individual speakers could vary a lot in their speech gestures due to their anatomy.
- The gestures compared in their paper were dorsal-coronal sequences, which are both tongue movements. As a suggested above, it’s not clear that these are two separate, independent gestures.
Ideally in the future, I would like to run an actual production experiment myself, because the Wisconsin X-Ray Microbeam database is not designed for this experiment and most of the recordings don’t have any useful tokens for comparison. This requires access to an Electromagnetic Articulography (EMA) machine (now the typical tool for this work), which I don’t currently have.
In the future, this work would also benefit from more cross-linguistic comparisons. Many languages have complex onsets which are not present in English, and it would be great to see further work on languages like Georgian.
There are a few assumptions made in my analysis which I address in the full paper, along with the appropriate visualizations. If you are interested, you can read the paper here. Additionally, please email me with any additional comments or questions.
References
-
Chitoran, I., Goldstein, L. & Bird, D. 2001. ‘Gestural Overlap and Recoverability: Articulatory Evidence from Georgian’. In C. Gussenhoven, T. Rietveld, and N. Warner (eds.) Papers in Laboratory Phonology 7, Cambridge University Press ↩︎
-
Mattingly, I.G. 1981. ‘ Phonetic representation and speech synthesis by rule.’ In The Cognitive Representation of Speech (T. Myers, J. Laver and J. Anderson, editors), pp.415-420. North Holland Publishing Company. ↩︎
-
Ohala, J.J. 1990. ‘Alternatives to the sonority hierarchy for explaining segmental sequential constraints.’ In Papers from the Chicago Linguistic Society 26: vol. 2, The parasession on the syllable in phonetics and phonology, 319-338. ↩︎